
Pythonはオープンソースで、ライブラリがたくさんあることや世界中に根強いファンがたくさんいることから、データ分析界隈ではRやMySQLと同様に人気の言語でしょう。
そんなPythonで人口の推移をヒートマップで表してみました。
環境はPython3+JupyterNotebook、Windowsです。
データについて
データはWikipediaのインドの人口を拝借しました。
参考:List of states in India by past population(Wikipedia)
各州の人口を1951年から2011年まで10年おきに最後に2019年の人口のデータがあります。
各州の中心となる(ヒートマップの円の中心)は州都の場所またはその州内の適当な座標です。
一部途中までインドではなかった場所などもありますが、Pythonでヒートマップを作ってみることが主題なのであまり細かく考えていません。
コード
|
1 2 3 4 |
#ライブラリのインストール import pandas as pd import folium from folium import plugins |
その後、データを取り込みます。
今回はWikipediaから作った核燃の人口と緯度経度のCSVデータをインストールします。
|
1 2 3 |
#データの取り込み population_df = pd.read_csv("OneDrive/IndianPopulation.csv",encoding="shift-JIS") population_df.head() |

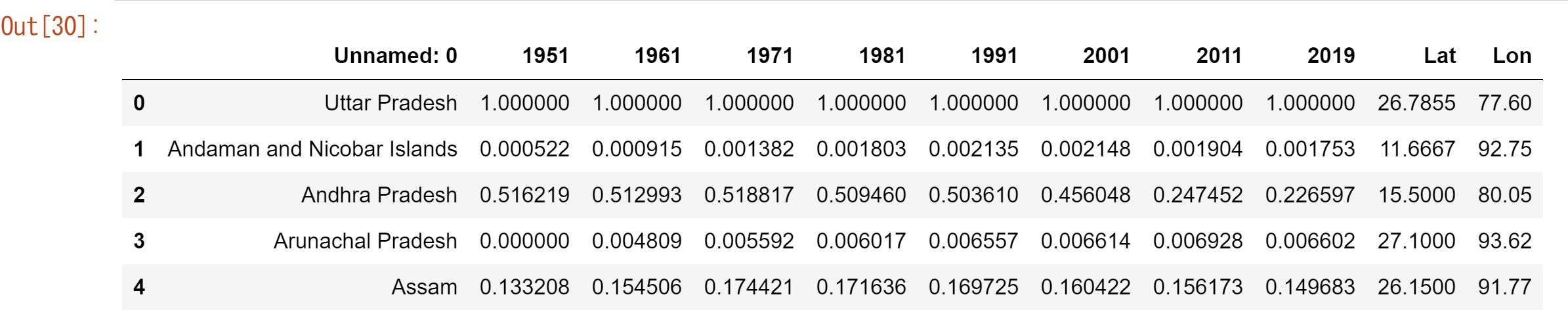
次に各州の人口の割合を各年で計算します。
|
1 2 3 4 5 6 7 |
#タイムインデックスの作成 time_series = ["1951","1961","1971","1981","1991","2001","2011","2019"] #各時間における、各州の人口割合を計算 for year in time_series: population_df[year] = population_df[year]/max(population_df[year]) population_df.head() |
計算した結果がこちら。
最後に地図上にデータを載せていきます。
|
1 2 3 4 5 6 7 8 |
#プロット用リスト作成 heat_data = [[[row['Lat'],row['Lon'], row[year]] for index, row in population_df.iterrows()] for year in time_series] #データリストを地図の上に追加 India_map = folium.Map(location=[20.5937,78.9629], zoom_start=5) hm = plugins.HeatMapWithTime(heat_data,index=[year for year in time_series],auto_play=False,radius=40,max_opacity=1,gradient={0.1: 'blue', 0.25: 'lime', 0.5:'yellow',0.75: 'red'}) hm.add_to(India_map) India_map |
実行結果がこちらです。
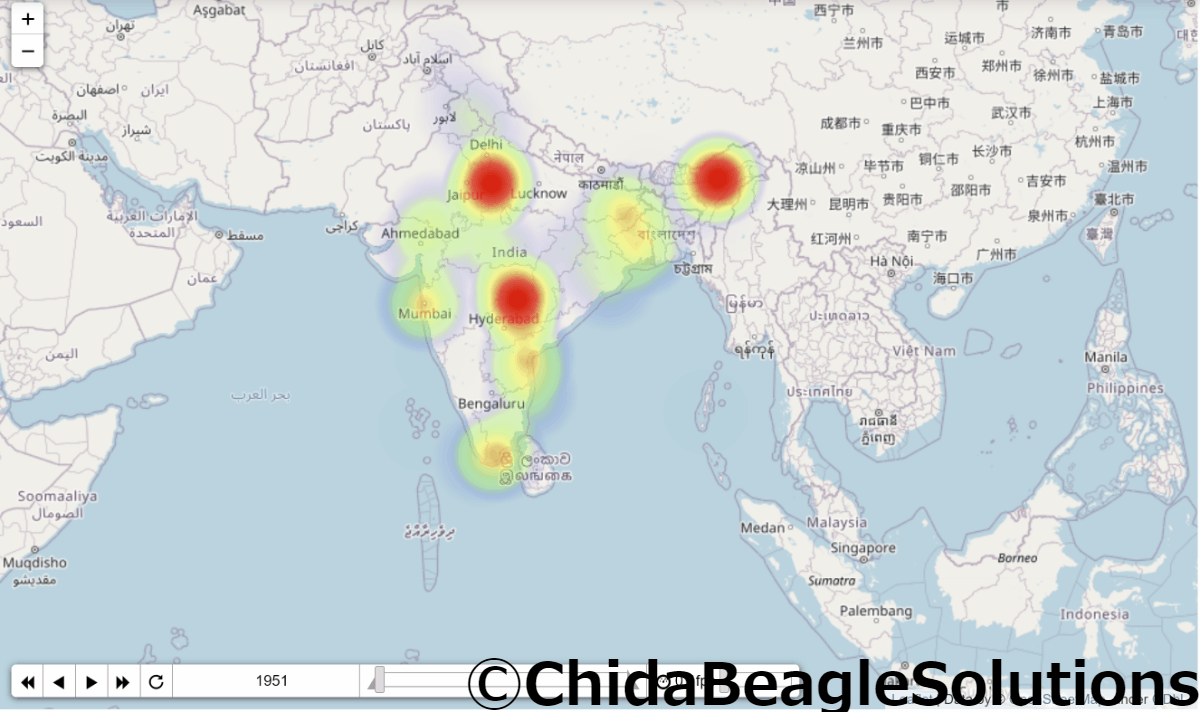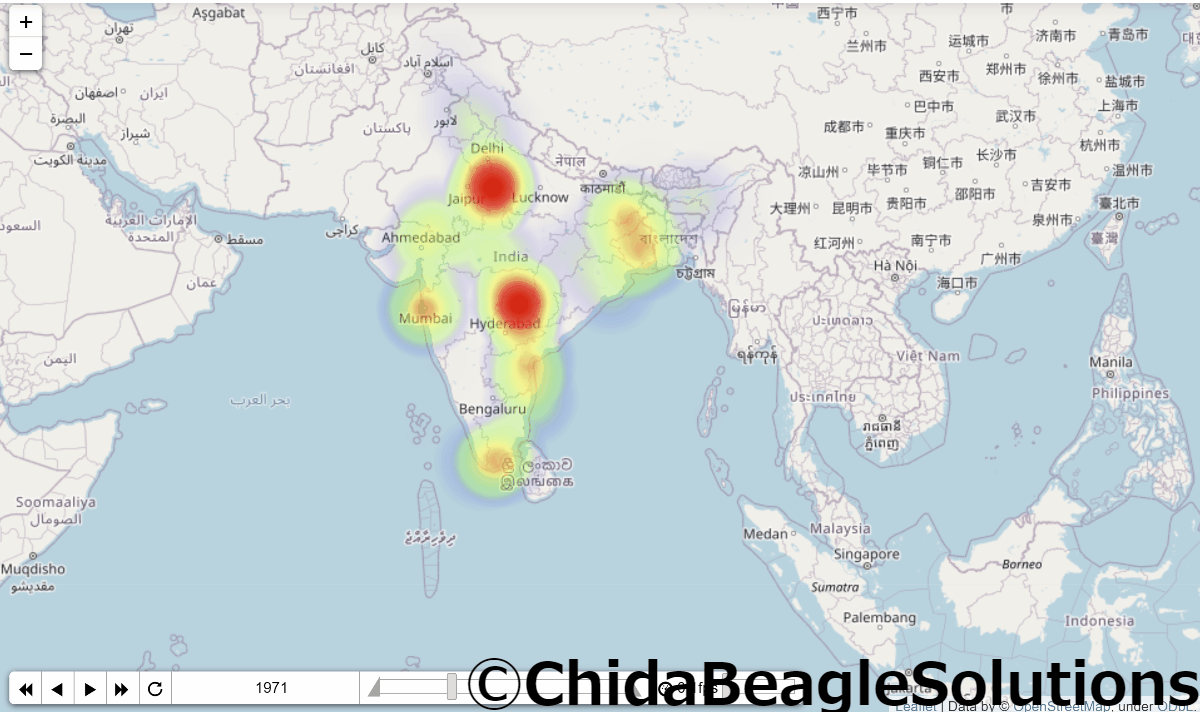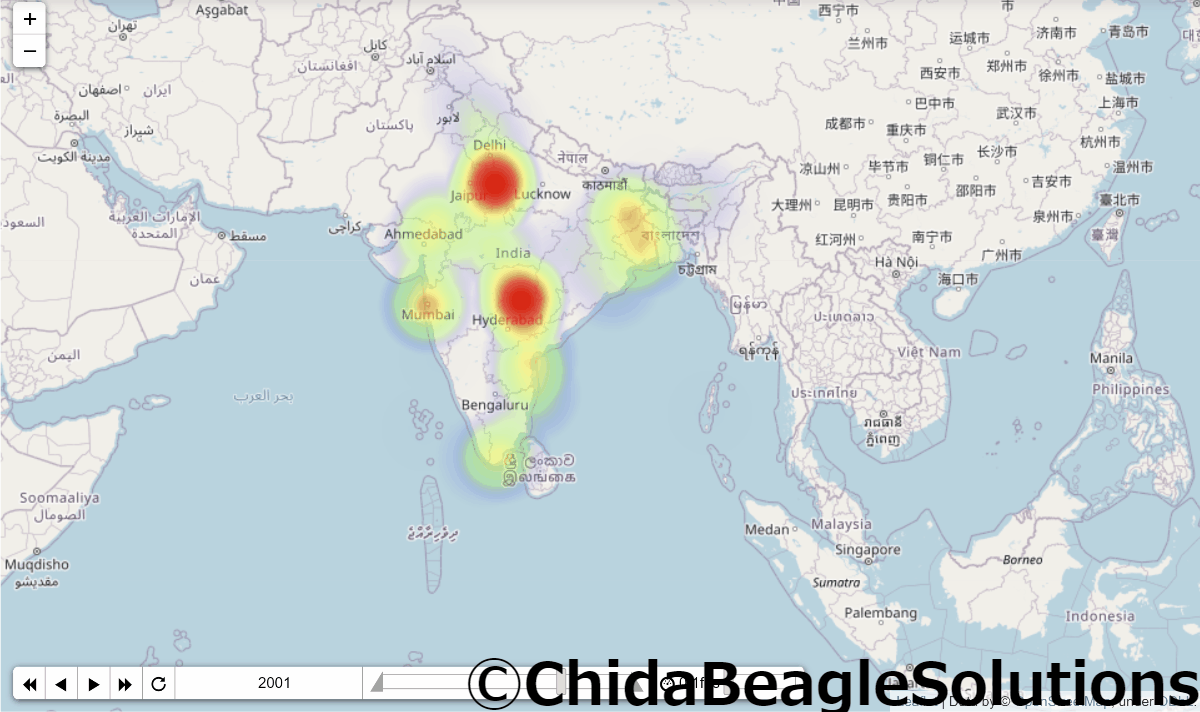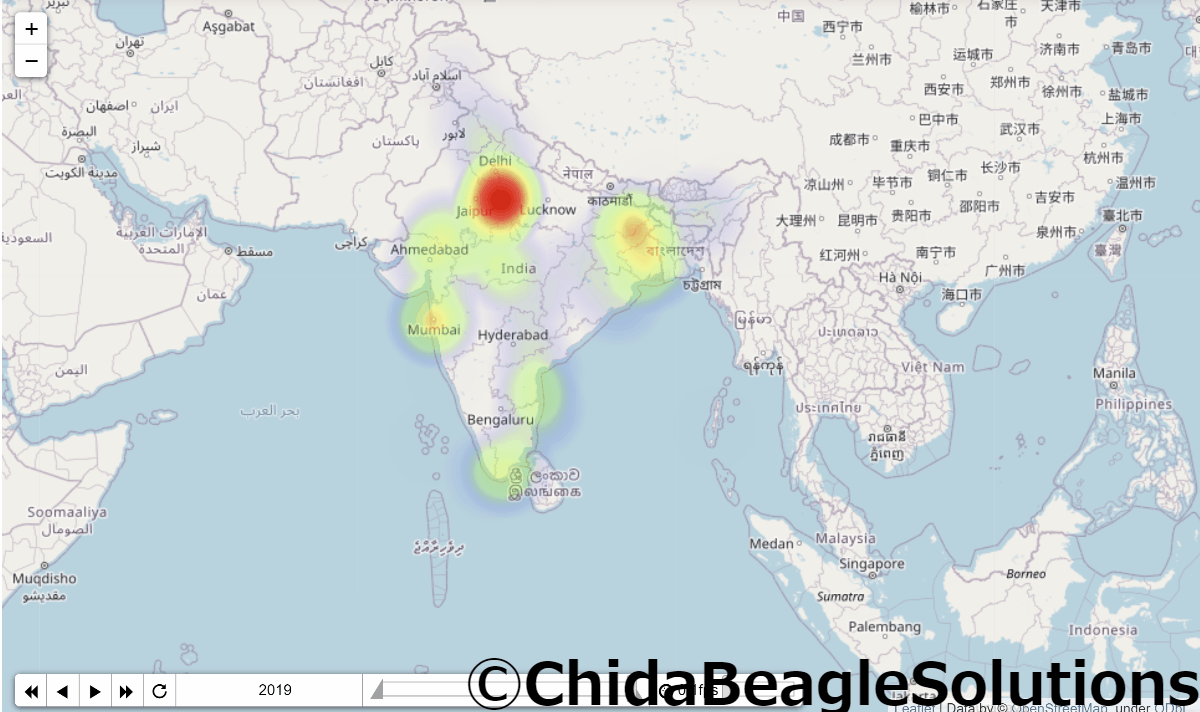
かわいいですね。
この図の問題として、各年毎の割合なので人口が増えていても、インド国内での人口の割合が増えていないと上の図では増えたように(より赤く)表示されない点です。
例えば、ボンベイのあるマハラシュトラ州の人口は1951年には32,002,500人で、2019年には123,144,223人と実に4倍近く増えています。(日本人と同じくらいいるやんけ!)
インド全体の人口増加から見るとそこまで人口が増えているため、そんなに赤さは変化していません。
またインドはデリーに人が密集しているため、デリーが真っ赤でほかの都市はあまり目立ちにくくなっています。
他の表示方法も考えたほうがいいのかも知れないですね。
CHIDA BEAGLE SOLUTINではこのようなデータのビジュアライゼーションも手掛けておりますのでご相談がある場合はお気軽にお問合せください!